Creative tools in the post-“deep fakes” world

Even if all research progress on AI stalled tomorrow, we would still have more than enough kinetic energy locked up in existing models, approaches and data to power a second renaissance in the visual arts. The power of visual creation for humans assisted by AI will be vast, porous and accessible.
Yes, it’s true that you can mentally substitute the phrase “AI” with “software” and often have a more intellectually honest description. But at the same time, software itself has not, until recently, understood the semantics of human experience in any meaningful way, and this is a slow-burning but important development.
When I worked as a machine learning researcher at Google, I was obsessed with the thought that, although search could spit out millions of results for, say, “apple”, the algorithm’s conceptual understanding of the term was nothing even remotely human. The algorithm had never been to the Apple store in Houston, nor had it ever bitten into a ripe Honeycrisp. Although the results are always highly clickable, this leads to an inhuman precision in its context: searching for “apple” returns the company, searching for “apples” returns the fruit.
Google’s bias for machine language over human language has inadvertent human cost, as coded language reveals deep rabbit holes and partitioned realities.
In the case of creative tools, and particularly in the case of visual creative tools, this kind of precision is already an enormous limitation: software that does to pixels and polygons exactly what the user said while completely oblivious to what the user actually meant.
The path forward is “smart” features that build in some knowledge about the visual context: in Photoshop, content-aware fill is often better than healing brush, magnetic lasso is often better than plain marquee selection, etc.
The question I want to pose is, what happens when the canvas itself understands the visual world in human terms, and can learn from human intent in context?
Artistic development and punctuated equilibria
"We become what we behold. We shape our tools, and thereafter our tools shape us."
— Father John Culkin, SJ
Eras of artistic flourishing in human history have always involved the innovation of tools and accessible methodology. Waves of artistic development are punctuated by the history of tools used for making art: Color photography (1861; James Clerk Maxwell), consistent point lighting (1420; Masaccio), linear perspective (1413; Filippo Brunelleschi), a chemical revolution in wet-on-wet oil painting (circa 1400; Jan van Eyck), all the way back to the first synthesis of blue pigment (circa 2500 BCE; Egyptian chemists mixing of limestone, malachite and quartz fired to 900℃), and papyrus (circa 4000 BCE).
"Since captured, “painted”, and synthesized pixel values can be combined seamlessly, the digital image blurs the customary distinctions between painting and photography. [An image] may be part scanned photograph, part computer-synthesized shaded perspective, and part electronic “painting” […] we have entered the age of electrobricolage."
— William J. Mitchell, “The Reconfigured Eye”, MIT Press 1992"
We don’t yet have the benefit of hindsight to describe the technology shift that is happening in visual creative tools today. Personally, I’m partial to William Mitchell’s term “electrobricolage”: searching for the right pixels to evoke an emotion not just from a single new photo, but combining them with pixels from from vast libraries of existing photographic material as well as purely synthesized ones. More punchier, perhaps, is to simply accept the slow bleeding overgeneralization of the term deep fakes.
Deep fakes as electrobricolage

Deep fakes originated as a kind of content-aware green screen for compositing faces onto existing videos, enabling a kind of semantic tinkering and improvisation with existing materials that was previously only possible for the most skilled video effects artists.
The technology quickly added new dimensions to questions of likeness and consent, and elicited concern from lawmakers and the intelligence community as to its obvious uses to confuse and decimate our already tenuous hold on fact-based reality [link].
But deep fakes has also gained real adherents in media, and found its way into commercial production pipelines. E.g., here is Ryan Staake, the director of @charli_xcx ’s newest music video, where the singer plays homage to the Spice Girls and other groups:
"the crew had a limited window to shoot the video, so they used deep fakes to avoid having to dress up the two singers as every single member of the bands."
and
"I think we’re definitely going to see more of this. It’s an utterly amazing tool."
The future of visual media is increased production value on shorter timelines and smaller budgets; mass communication micro-targeting with more precision new personalized creative channels. For example, Adobe estimates that “content creators and brands are responsible for creating 10 times as much content as they did last year, but with the same amount of staff.”
The process of creating content, however, remains frustratingly manual: artists spend much more time executing than they do ideating.
The Creation Economy
The potential of AI-augmented visual creation is much more than automating simple repetitive tasks. This leap in our tools means new, welcoming ways to create and tinker—new, democratized creation. I can’t paint, but I do have aesthetic preferences and I can work together with a deep neural network to dial them in wholesale.


Whether or not “AI” will replace human creativity isn’t the right question. What is important is how resources will ultimately be reallocated according to the new capabilities unlocked. Scott Belsky believes that visual communication is the future of labor:
"As jobs become increasingly automated or commoditized, the future of labor favors those with creativity and the skills to communicate visually. It’s one of the reasons i jumped back in @Adobe, and why we need to make creative tools more accessible + powerful"

And this is a part of a bigger reversal we’re seeing in the tech sector: the switch from the “attention economy”—internet as consumption—to the “creation economy”—internet as production.
"Perhaps anecdotal, but it feels that there’s been some swing from “attention economy” to “creation economy” over the past few years: @airtable, @figmadesign, @github revival under MS, @Patreon, etc."
— Patrick Collison @patrickc (link)
Millions of tiny sliders
What will these new creative tools look like? With tens or even hundreds of millions of parameters, most deep learning models are over-specified, redundant and mind-numbingly complex. In the traditional paradigm, we gave artists full control: one adjustment slider for every parameter of the algorithm. Things like exposure, contrast, and blur radius. However, in the deep fakes era, the answer is not “millions of tiny adjustment sliders,” one for the value of each neuron.
Rather, I believe there are two classes of UI primitives that will prove most interesting:
- Adjustment by analogy, e.g., “make this more like this” or “make the relationship between these two things match the relationship between these other two,” and
- Structured exploration, e.g., exposing higher-order “adjustment sliders” that wrap up entire concepts like face pose, hair color or lighting into a single parameter value. Exposing such “latent structure” in data is one of the super powers of deep learning.
Researchers at NVIDIA published a paper late in 2018 that allows a user to generate the most photorealistic faces we have seen to date (A Style-Based Generator Architecture for Generative Adversarial Networks [video]; Tero Karras, Samuli Laine, Timo Aila).
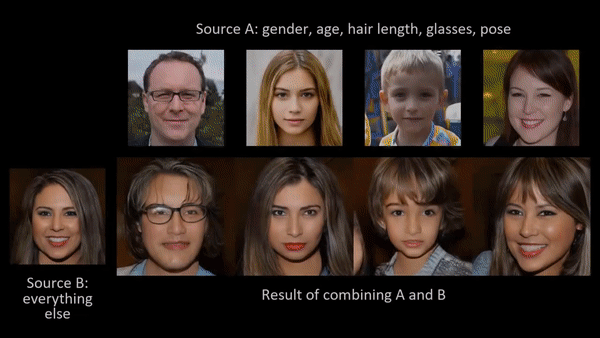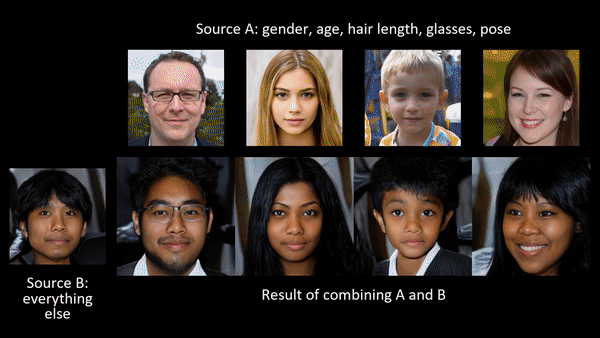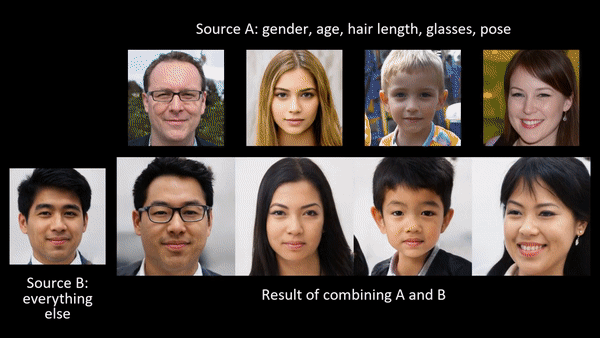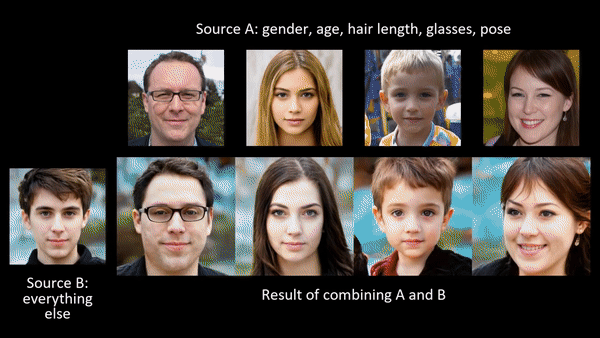
In addition to producing photorealistic faces through analogy (e.g. make this face A look like this other one B), the “latent structure” of these models can be shown to encode physical constraints about the world. For example, rotations in 3D space:
"An exciting property of style-based generators is that they have learned to do 3D viewpoint rotations around objects like cars. These kinds of meaningful latent interpolations show that the model has learned about the structure of the world." — Ian Goodfellow
Latent structure can be thought of metaphorically as semantic or structural adjustment sliders controlling abstract properties of the object or scene: age, gender, orientation in space, lighting conditions, and more.


We can learn to leverage this latent structure, applying additional physical constraints to, e.g., synthesize motion by that was never captured during the film shoot by example alone (Everybody Dance Now [video]; Chan, Zhou and Efros).
Similar UI paradigms exist for “style transfer”—a class of algorithms that can match some kinds of artistic and illustrative style between source and destination images (e.g. palettes, brush contours, and color regions).

These algorithms are not yet suitable for photorealistic synthesis, but can be used in limited domains for texture replacement and color normalization across assets.
Furthermore, the latent dimensions of style space can be explored by the artist through interpolation between archetypal styles (A Style-Based Generator Architecture for Generative Adversarial Networks; Daan Wynen, Cordelia Schmid, Julien Mairal).

Color and style matching by example is a more natural expression of artistic intent, and maps more directly to our visual experience than precision tools like “curves” or “adjust histogram”.
Facet
Facet is building a content-first editing studio that bridges the gap between tool and assistant, freeing artists, photographers and retouchers to explore new ideas directly in terms of human-level visual concepts: faces, clothing, skin-tones, backgrounds, and more.
Much like you might browse Getty images for the right bit of stock photography or hire a photographer or fashion designer known for a particular aesthetic, Facet studio allows you to “dial in” the image assets you wanted through a combination of analogy and search through latent visual structure.
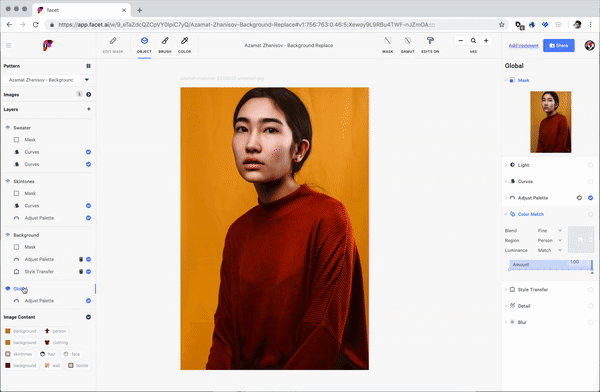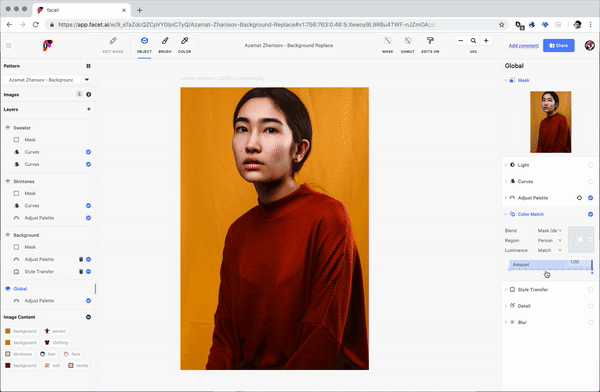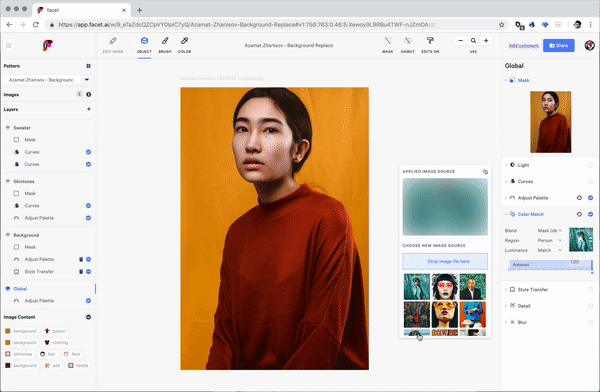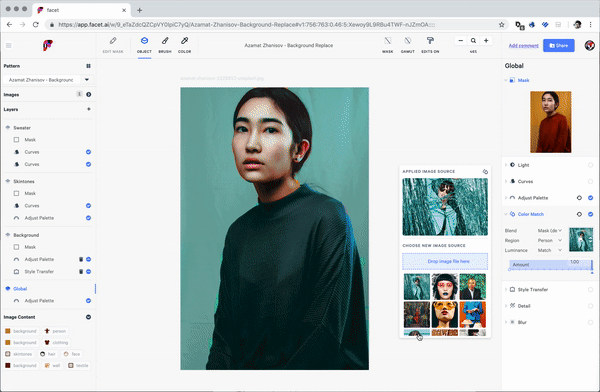
Facet studio gives the artist full control over still images, photoshoots and video content, synthesizing local photographs, stock photography, rendering and generative models, replacing millions of tiny sliders with more humanistic direction by analogy and example.
Ultimately, Facet helps unlock Mitchell’s future where “captured, painted, and synthesized pixel values can be combined seamlessly.” More to the point, we believe such “electrobricolage” can be reduced to something much simpler: search through a space of images that don’t exist yet.
I’ve outlined a bit about our philosophical stance on the new issues and awesome potential for creative work. If you’re interested in the future of content-aware photo, stop-motion, and video-editing, we have a ton more to share with you. Also, Facet is hiring! So don’t hesitate to drop us an email.
Sign up for more thoughts on the future of creative work at https://facet.ai
—jr